
Data Lineage Granularity
What are the levels or layers of lineage?
It's critical to understand how deep your lineage can go and where to dive in.

Depth of Data Lineage
Data lineage can be as automated or manual as needed, and has various levels of depth and breadth. To be able to maximize your efficiency, you may find it helpful to move between levels of granularity and to stack each layer to build a comprehensive overview of your data. But, you must first understand where to get started.
To help you understand these layers of lineage, we've compiled a few terms to keep in mind when considering a data lineage software. The following can be considered the depth of lineage:
Column-Level (Attribute Level) Lineage
This is the most granular level of lineage. Column-level lineage allows tracing individual properties or attributes and answers specific questions. For example, this level can be used to address questions such as “how has the profitability number been calculated?”
This level of lineage is the hardest to achieve simply due to scale. If every system has 100 datasets and each dataset has 100 attributes, then you’d be tracking 10k attributes (and their interactions) in total. Often, this is seen as too detailed but at the same time, only attribute level lineage enables automated use of lineage to answer questions about specific attributes.
Manta can help you tackle column-level lineage, saving you time and money.
Business Lineage
This is the easiest level of lineage to consume by non-technical users. This is often manually built, which is a costly and time consuming process that can quickly become outdated. It is best built by using automated technical lineage (column-level lineage) overlaid with a conceptual model to put lineage into simplified business terminology.
System or Application-Level Lineage
System or application-level lineage is often used by enterprise architects to understand the interconnections and dataflows between systems on a very high level, which is then delegated to their respective teams.
This is the level most companies start with when designing lineage manually. There are a handful of systems of interest at the beginning and using a manual approach makes it possible to cover the interconnections in a few days.
Dataset-Level Lineage
Dataset-level lineage goes one level deeper than application or system level lineage. It covers lineage on the level of entities that most teams work with (e.g. a Customer, Product). This is sometimes referred to as "conceptual" or "modeling" lineage.
This level actually gains importance with adoption of the Data Mesh concept, where Data Products are often groups of entity data, and understanding the origins of this data is often important for consumers. At the same time, understanding the usage of data products is important for their owners/producers.
Market Guide
Ataccama 2022 State of
Data Quality Report

Find the Right Level of Lineage for Your Organization
Linking depth, breadth, and approach of various granularities of lineage is not an easy task to do.
Think of it as creating a map of your road network of the US today - now that you have all the roads built, how do you actually create a map? Do you start with coast-to-coast highways, but then are lost on the “last-mile” problem? Or do you start building a detailed map of a town, but miss the big picture of the country? Or do you do it completely differently, e.g. by monitoring traffic and speed using cellphone positions? Different approaches provide different coverage, levels of accuracy and detail. Data lineage is similar - different approaches are suited for different use cases and to address different needs.

Steps to Find the Granularity of Lineage You Need
Step 1
Consider the project or outcome you want to use the lineage to achieve. This gives you level of detail and coverage needed from a depth and breadth perspective.
Step 2
Choose the approach to collect it.
Please note that the approach may be different for the environment that you already have built and for the environment that you are going to build. With the latter, you can design the environment with lineage in mind, e.g. developers can use some tagging libraries to generate the lineage info both design and runtime.
Step 3
Consider scalability.
We often see two approaches that are destined to fail: (1) start manually with low-coverage low-detail and then try to cover end-to-end space in a higher-level of detail by distributing the responsibility for building it to individual teams. Or (2) we see a "boil the ocean" approach without milestones or smaller goals where lineage can be used and proven. Then, when you start scaling you realize the approach that was once optimal does not actually scale well and you need to change.
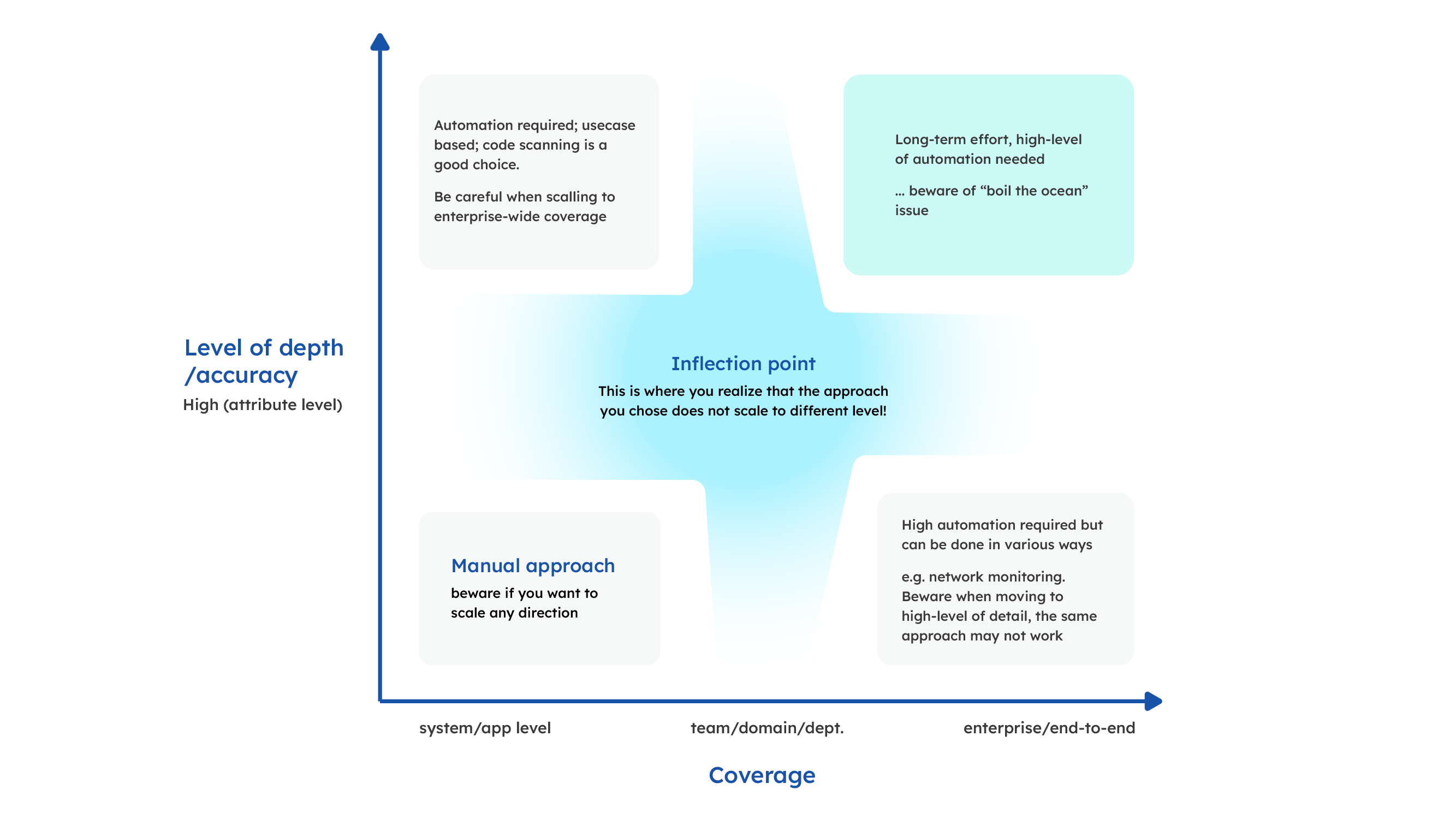
We recommend that you plan what you want to achieve in the long term. Consider which level(s) of detail will be needed (bearing in mind that you can always aggregate detailed lineage to high-level in an automated fashion, but it does not work the other way around); and use an agile/project based approach. Do not try to boil the ocean. Instead, find where lineage of particular level of detail and accuracy is needed and build it using the right approach to fit into the long-term goal.

Let’s Talk
Ready to dive into the sea of data? Schedule a demo with our team to see how we can help.
