When you’re building a metadata repository in your data warehouse, it always comes down to a hard choice: which type of database is going to be more useful for you? Let’s take a look at two types: traditional relational databases vs. fresh new graph databases. Relational databases have been commonly used as metadata repository because this specific kind of technology has already been employed at many data warehouses. But since data lineage is a kind of a graph, it only makes sense to try a graph database to work with it.
We were helping with the construction of a metadata repository for one of our client’s data warehouses, and we decided to test the existing solutions. We settled on PostgreSQL 9 and Neo4j 1.8.3. Why did we choose those two?
Benchmark settings
The goal of our benchmark was simple: to create a metadata repository and retrieve stored information in a way typical for metadata management operations. It was a two-phase process:
Parse & Merge Phase
Analyze the transformation script, which creates a graph of the static and dynamic connections between objects. Merge this graph into a metadata repository.
Request Phase
Test the response of each type of repository and compare them.
We prepared 4 sets of metadata for our test. The biggest one was marked as “1” and consisted of a huge number of different input scripts using different technologies. First, we needed to parse them and then merge them into the database. Our input scripts were taken from one of our customer’s data warehouse; they were BTEQ (Basic Teradata Query) and DDL scripts running on the Teradata database. The other sample sets were derived from the big one and consisted of a portion of the original set:
The Parse and Merge Phase was implemented in Java. The parser was the same for both the test subjects, and the merger was customized for each type of database. When requesting stored data, we used special interfaces for each database type. For PostgreSQL, we used SQL with a set of PLPgSQL functions. For Neo4j, we used the language Cypher.
What did we measure?
We measured both phases according to the following criteria:
Parse & Merge Phase
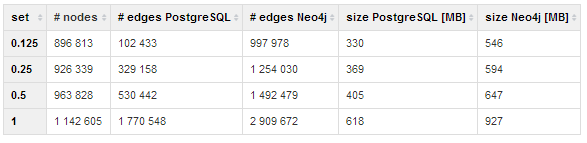
1. Time to create a new database (in milliseconds)
2. Size of a new database of metadata repository (in MB of disk space
Request Phase
We ran two types of requests on databases of each size:
1. To find an exact node by name or a part of its name
2. To find what was around this node
Implementation of PostgreSQL and Neo4j
Let’s dig a little deeper and take a look at how our chosen database technologies work.
The PostgreSQL database is made of five different tables connected by foreign keys. It is also possible to use hierarchical requests based on WITH construction, which is a part of SQL99 standard. Doing it like this is usually not very fast anyway, and it’s not very comfortable if you’re using three other different sets of scripts based on a bigger one. Using WITH would be a real problem.
Neo4j is one of those “schema free” databases. The data model already includes nodes and edges both of which can have an unlimited number of attributes. Attributes always have a name and scalar value (number, string, timestamp). Every node or edge can have a totally different set of attributes. Edges also have another mandatory attribute, LABEL. We used three types: PARENT, FILTER and DIRECT according to our conceptual design of the data scheme. Edges in Neo4j are already oriented, but it’s easy to send requests in both directions. The nodes in our implementation had the attributes resource_name, node_name and node_type. Neo4j automatically creates indexes of node and edge IDs. It’s also possible to create indexes of attributes, which makes searching for reference nodes way easier.
Results
So what was the result of our test in its phases? How did the “old school” relational database perform against the “newbie” graph database?
Parse & Merge Phase
First, two tables showed how fast both database systems were when it came to inserting data into the repositories. Our computer for parsing and merging had these specs:
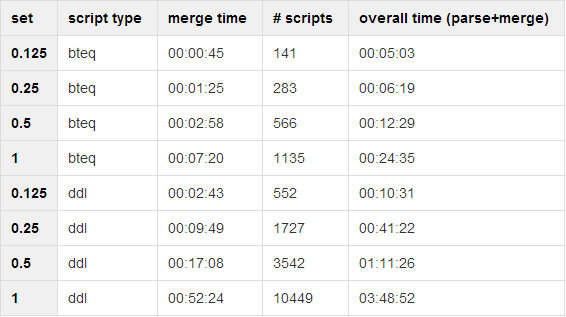
When it came to solution comparison, the third column, “time (merger)”, was the most important. Our sample sets had two types of scripts (BTEQ and DDL). The application parsed BTEQ scripts first and then DDL scripts. When the parsing was done, the application had its graph representation and started to merge it into the repository. We measured that time, and that was our result.
PosgreSQL
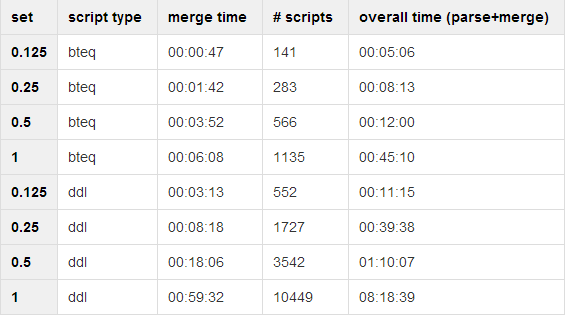
Neo4j
As you can see, time increases with increases in the size of the script set (no surprises there). But, more importantly, there is no big difference between PostgreSQL and Neo4j.
Request Phase
The second round of testing measured the time needed to access data stored in the repositories during the Parse & Merge Phase. Our testing machine for the Request Phase had these specs:
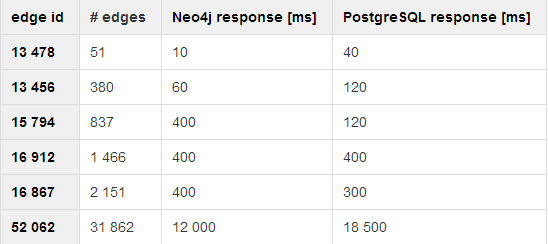
We started with smaller datasets, but we weren’t able to get any meaningful results since requesting was super fast with both technologies. We ran it a couple of times, but still no measurable results. On bigger sets, we were finally able to get some results, so we put them into this nice table:
Note: What tools did we use for our measurements? The “\timing on” option in psql client and Neo4j console sends back response times automatically.
Both systems were tested multiple times and there was a significant decrease in response time after the second run. It was most likely caused by PostgreSQL cache and Java Virtual Machine JIT optimization in the case of Neo4j. The decrease in response time did not differ between the two platforms.
But when it comes to results, it’s actually pretty bad for Neo4j. It’s a graph database, so it should not be so slow, when you’re accessing stuff which is graph-based already. So, what happened? After some digging, we tried to change the Neo4j client. Even though Cypher is a native client for graph databases (!) it did not perform very well. So we went for direct Java API implementation to access Neo4j databases and ran it again to compare our “old” Cypher client with a fresh new client custom-made in Neo4j Java API. We ran it on these specs:
And got these results:
It’s quite obvious that Cypher is way slower than custom Java API solution.
Conclusion
Let’s sum it up. What do we know after testing two different types of repositories with three different clients (one on PostgreSQL + two on Neo4j)? Which performs better when it comes to creating a repository with a large set of scripts and then requesting specific information from it? Our results are definitely not bulletproof – different machines and a relatively low number of repetitions do not help, but the sets of scripts were authentic.
So what is our recommendation? It always depends on the circumstances and needs of the actual data management solution, but speed usually matters more than size. From the POV of this test, it’s much more reasonable to implement the Neo4j Java API solution than the “official” Cypher.
Since PostgreSQL and Neo4j are not the only relational and graph databases out there, we are preparing other benchmarks to see what’s good for Manta and other projects. We will share the results with you here on our blog and on Twitter, or upon request via email. Co-author of this text is Tomáš Fechtner, consultant at Profinit and member of Manta Tools team.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}